About 8 months ago my team and I were facing the challenge of building our first Deep Learning infrastructure. One of my team members (a brilliant data scientist) was working on a prototype for our first deep model. The time arrived to move forward to production. I was honored to lead this effort.
Our achievements: we built an infrastructure that ranks over 600K items/sec, our deep models have beaten the previous models by a large margin. This pioneer project has led the way for the subsequent Deep Learning projects at Taboola.
So the prototype was ready, and I was wondering: how to go from a messy script to a production ready framework? In other words, if you are into establishing a deep model pipeline this post is for you.
This blog post is focused on the training infrastructure, without the inference infrastructure.
Prerequisites
Assume you have basic knowledge in:
- Python
- Train Machine Learning model
- TensorFlow
- Docker
Let’s take one step back and think…Ideally such a training infrastructure should support:
- Comfortable development environment
- Portability among environments
- Run on CPU/GPU
- Simple & Flexible configuration
- Support Multiple Network Architectures
- Packaging the model
- Hyper Parameter Tuning
One mantra to keep in mind:
‘Speedy Gonzales Time to Market’ == ‘no over engineering!’ == ‘Keep it simple’
Enough with the baloney, let’s get down to business:
Technology stack
BigQuery, Google Storage (GS), Python, Pandas, TensorFlow, Docker, and some other Python nice libraries: fabric, docker-py, pyformance & spacy
Comfortable development environment
This makes the whole team move faster, plus putting a new team member into action is super easy. To achieve this we did 2 things:
The first was using a small dataset for sanity training, a JSON file with 2K rows. Used both for testing on a developer machine and for sanity automation tests. This is very helpful for quick testing your code changes.
The second is a project management script (just one big Python script).
We implemented a simple command line tool using ‘fabric’ (Python library). Here are few example commands:
$ fab --list Available commands: init_env initializes Python virtual environment & installs 3rd party test runs unit tests train runs sanity training train_all runs sanity training on all model variants docker_build builds snapshot Docker image docker_test same as test, only from inside the Docker image docker_train same as train, only from inside the Docker image
Using docker-py library was very useful for the Docker stuff.
CI tasks were also added to this script (used by Jenkins build agent).
High level flow
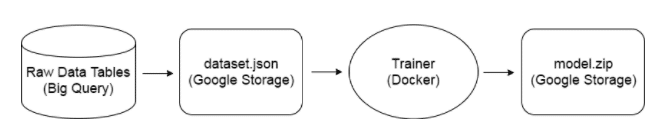
Dataset is generated from raw data tables in BigQuery and stored as a JSON file in GS.
Then the training process kicks in: download the dataset, train the model, and export the model back to GS (to some other path).
Fit dataset into memory
Not always possible, but it was for us. Our dataset contains about 5M rows (~ 4GB JSON file). The JSON file is loaded into pandas’ DataFrame for pre-processing, then split into train & test. This approach is simple to implement, gaining fast training run time. If the dataset does not fit into the memory, a quick (maybe temporary) solution could be subsampling it.
Portability among environments
No more “It works on my machine”! By using Docker, training runs the same on the developer machine, automation and cloud environments. Training input & output is stored in GS, no matter where the training process ran.
Running on CPU/GPU
- Install both TensorFlow GPU and CPU versions (in the project management script: use the GPU for production training and the CPU for development and testing)
- Use NVIDIA Docker base image – note that the CUDA version should match the TensorFlow version (see more instruction on TensorFlow’s website)
FROM nvidia/cuda:8.0-cudnn5-devel RUN pip install virtualenv==15.0.3 RUN virtualenv --system-site-packages /venv-cpu RUN virtualenv --system-site-packages /venv-gpu RUN chmod +x /venv-cpu/bin/activate RUN chmod +x /venv-gpu/bin/activate COPY ./requirements.txt /tmp/requirements.txt RUN /venv-cpu/bin/pip install -r /tmp/requirements.txt RUN /venv-gpu/bin/pip install -r /tmp/requirements.txt ENV MY_TF_VER 1.1.0 RUN /venv-gpu/bin/pip install https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-$MY_TF_VER-cp27-none-linux_x86_64.whl RUN /venv-cpu/bin/pip install https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-$MY_TF_VER-cp27-none-linux_x86_64.whl
- Use nvidia-docker command line tool – a thin wrapper for Docker command line. It enables the Docker container to use the GPU
Simple & flexible configuration
Flexible for research, live models & hyper parameter tuning. Configuration should be simple to reason – I have seen too many configuration mechanisms get out of hand. I think we found a fair trade off between flexibility and simplicity:
First, no hierarchies! (keep it as simple as possible).
For example:
Hierarchies are Bad:
-- pre_prossesing: -- subsample_ration = 0.3 -- training_loop -- batch_size = 124 -- epochs = 100 -- hyper_param -- learining_rate = 0.1 ….
Flat is Good:
-- subsample_ration = 0.3 -- batch_size = 124 -- epochs = 100 -- learning_rate = 1.1
Config values are set in 3 levels:
Level 1 – NetConfig class:
class NetConfig: def __init__(self, graph='deep_v1', batch_size=256, learning_rate=0.001 ): ….
As you can see default values are hard coded as part of the configuration class.
Level 2 – variant_config.json:
"variant_1":{
"learning_rate" : 0.001
},
"variant_2"{
"graph": "deep_v2",
"batch_size": 124
}
Here we define our model variants. Only overriding non default configurations.
The configuration file is held with the code, and baked into the Docker image. A new Docker image is built for every configuration change.
Level 3 – environment variable:
nvidia-docker run -e batch_size=64 ….
Using environment variable enables overriding a specific configuration for a single training run. We use it for research and hyper parameter tuning.
Support Multiple Network Architectures
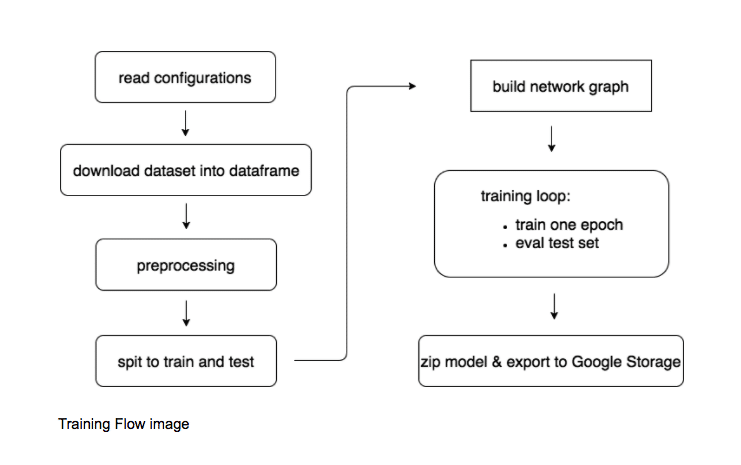
Supporting multiple network architectures is a key concept for us. It enables many team members to work in parallel on different architectures (and set A/B tests on live traffic).
So how do we support multi network architectures? Let’s take a closer look into ‘build network graph’ step:
def build_model_graph(net_config, dataset_shapes, tf_session): if config.graph == ‘deep_v1’: return build_graph_deep_v1(net_config, dataset_shapes, tf_session) elif config.graph == ‘rnn_v1’: return build_graph_rnn_v1(net_config, dataset_shapes, tf_session) ...
‘build_graph_deep_v1’ & ‘build_graph_rnn_v1’ are just static methods that contain the TensorFlow code for defining the graph.
‘build_model_graph’ returns an OpsWrapper instance, holding the TensorFlow ops for the training loop:
class NetOps:
def __init__(self,
batch_size_placeholder,
dropout_placeholder,
input1_placeholder,
input2_placeholder,
loss_op,
train_op
….
)
Note that the ‘build_model_graph’ has 3 inputs: net_config (discussed earlier), dataset_shapes and tf_session. The dataset_shapes object is created during the preprocessing step. It contains features vector information that is used to build the network graph. For instance, the cardinality of a categorical feature is used to define the size of the embedding lookup table.
class DatasetShapes: def __init__(self, input1_cardinality, Input2_cardinality, num_of_unique_words, sentence_max_size … )
The tf_session in just an instance of tf.Session class.
Packaging the Model
Packaging the model TensorFlow files inside a zip with other extra files, can help debug and monitor the training process. What extra files did we store?
- TensorBoard files
- Graph image of train & test offline metrics
- Offline metrics CSV:
- > row for each epoch
- > add all kinds of offline metrics, such as train & test error & loss
- DeFacto configuration – used to train the model
- Dataset metadata – for example dataset size
- Other things you may find useful for troubleshooting & debugging
Hyper parameter tuning
Hyper parameter tuning is critical. A big improvement on model performance can be gained by tuning parameters such as, batch size, learning rate, embedding dimension, hidden layer depth, width, and so on….
We started by implementing a simple Python script that runs a random search on the hyper parameter space. It runs sequentially using a single GPU. We just ran it for days. To get faster and better results we moved to the cloud, running in parallel on multiple machines & GPUs.
All-in-all we had lots of fun working on this project (at least I did). We ended up with a relatively simple and straightforward infrastructure, being used by the whole team, raising somewhere between 10-15 live A/B tests in parallel.
That is it! I hope you find it useful.
Special thanks to my team: Yedid, Aviv, Dan, Stavros, Efrat and Yoel.